 电子发烧友App
电子发烧友App


贝叶斯定理提供了一种由P(c),P(x)和P(x | c)计算概率P(c | x)的方法。 看下面的等式:

其中:
P(c | x)是在x条件下c发生的概率。
P(c)是c发生的概率。
P(x | c)在c条件下x发生的概率。
P(x)是x发生的概率。
示例:
让我们用一个例子来理解它。 下面我有一个天气和相应的目标变量“玩游戏”的训练数据集。 现在,我们需要根据天气条件对玩家是否玩游戏进行分类。 我们按照以下步骤执行。
步骤1:将数据集转换为频率表
步骤2:通过发现像“Overcast”概率= 0.29和播放概率为0.64的概率来创建似然表。
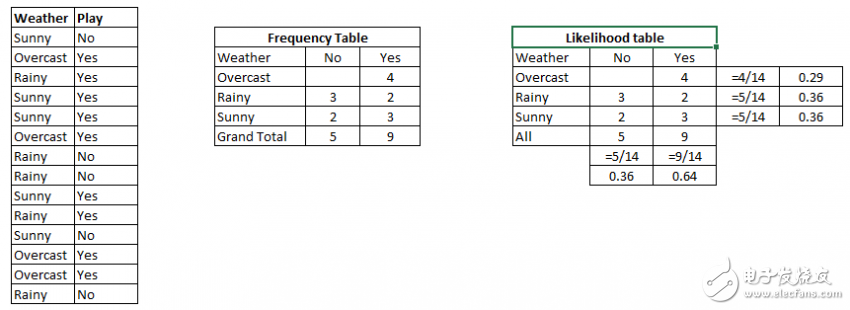
步骤3:现在,使用朴素贝叶斯方程来计算每个类的概率。 其中概率最高的情况就是是预测的结果。
问题:
如果天气晴朗,玩家会玩游戏,这个说法是正确的吗?
我们可以使用上述方法解决,所以P(Yes | Sunny) = P( Sunny | Yes) * P(Yes) / P (Sunny)
这里,P(Sunny | Yes)= 3/9 = 0.33,P(Sunny)= 5/14 = 0.36,P(Yes)= 9/14 = 0.64
现在,P(Yes | Sunny)= 0.33 * 0.64 / 0.36 = 0.60,该事件发生的概率还是比较高的。
朴素贝叶斯使用类似的方法根据各种属性预测不同分类的概率,该算法主要用于文本分类和具有多个类的问题。
Python Code
#Import Library
from sklearn.naive_bayes import GaussianNB
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create SVM classification object model = GaussianNB()
# there is other distribution for multinomial classes like Bernoulli Naive Bayes, Refer link
# Train the model using the training sets and check score
model.fit(X, y)
#Predict Output
predicted= model.predict(x_test)
R Code
library(e1071)
x <- cbind(x_train,y_train)
# Fitting model
fit <-naiveBayes(y_train ~ ., data = x)
summary(fit)
#Predict Output
predicted= predict(fit,x_test)
6. KNN (K-近邻算法)
它可以用于分类和回归问题, 然而,它在行业中被广泛地应用于分类问题。 K-近邻算法用于存储所有训练样本集(所有已知的案列),并通过其k个邻近数据多数投票对新的数据(或者案列)进行分类。通常,选择k个最近邻数据中出现次数最多的分类作为新数据的分类。
这些计算机的距离函数可以是欧几里德,曼哈顿,闵可夫斯基和汉明距离。 前三个函数用于连续函数,第四个函数用于分类变量。 如果K = 1,则简单地将该情况分配给其最近邻的类。 有时,选择K在执行KNN建模时是一个难点。
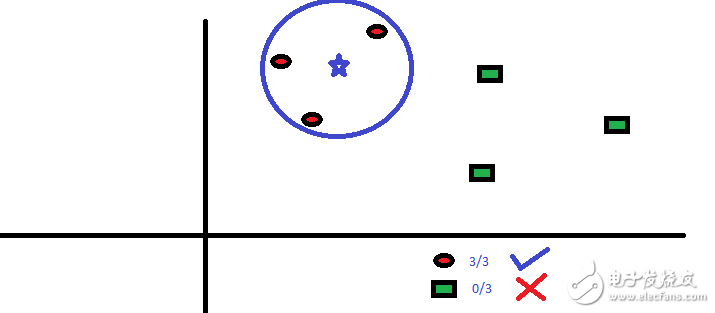
KNN可以轻松映射到我们的现实生活中。 如果你想了解一个人,你没有任何信息,你可能想知道先去了解他的亲密的朋友和他活动的圈子,从而获得他/她的信息!
选择KNN之前要考虑的事项:
KNN在计算上是昂贵的
变量应该被归一化,否则更高的范围变量可以偏移它
在进行KNN之前,预处理阶段的工作更像去除离群值、噪声值
Python Code
#Import Library
from sklearn.neighbors import KNeighborsClassifier
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create KNeighbors classifier object model
KNeighborsClassifier(n_neighbors=6) # default value for n_neighbors is 5
# Train the model using the training sets and check score
model.fit(X, y)
#Predict Output
predicted= model.predict(x_test)
R Code
library(knn)
x <- cbind(x_train,y_train)
# Fitting model
fit <-knn(y_train ~ ., data = x,k=5)
summary(fit)
#Predict Output
predicted= predict(fit,x_test)
7. K-Means
它是解决聚类问题的一种无监督算法。 其过程遵循一种简单而简单的方式,通过一定数量的聚类(假设k个聚类)对给定的数据集进行分类。 集群内的数据点与对等组是同构的和异构的。
尝试从油墨印迹中找出形状?(见下图) k means 与这个活动相似, 你通过墨水渍形状来判断有多少群体存在!
下面两点感觉原文解释的不是很清楚,自己然后查了下国内的解释方法
K-means如何形成集群
(1) 从 n个数据对象任意选择 k 个对象作为初始聚类中心;
(2) 根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分;
(3) 重新计算每个(有变化)聚类的均值(中心对象)
(4) 循环(2)到(3)直到每个聚类不再发生变化为止参考














 工商网监
工商网监
评论