 电子发烧友App
电子发烧友App


R Code
x <- cbind(x_train,y_train)
# Train the model using the training sets and check score
logistic <- glm(y_train ~ ., data = x,family='binomial')
summary(logistic)
#Predict Output
predicted= predict(logistic,x_test)
3.决策树
这是我最喜欢的算法之一,我经常使用它。 它是一种主要用于分类问题的监督学习算法,令人惊讶的是,它可以适用于分类和连·续因变量。 在该算法中,我们将群体分为两个或多个均匀集合。 这是基于最重要的属性/自变量来做出的并将它们分为不同的组。关于决策树的更多细节,你可以阅读决策树简介
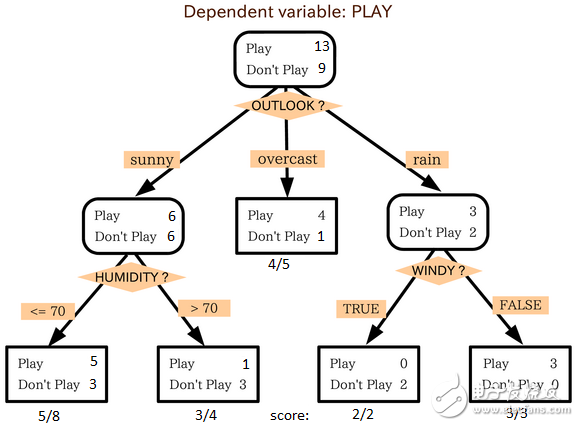
在上图中,您可以看到根据多个属性将群体分为四个不同的群组,以确定用户“是否可以玩”。为了 将人口分为不同的特征群体,它使用了诸如Gini,信息增益,卡方,熵等各种技术。
了解决策树如何运作的最佳方法是播放Jezzball - 微软的经典游戏(下图)。 大体上就是,来一起在屏幕上滑动手指,筑起墙壁,掩住移动的球吧。
Python Code
#Import Library
#Import other necessary libraries like pandas, numpy...
from sklearn import tree
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create tree object
model = tree.DecisionTreeClassifier(criterion='gini')
# for classification, here you can change the algorithm as gini or entropy (information gain) by default it is gini
# model = tree.DecisionTreeRegressor() for regression
# Train the model using the training sets and check score
model.fit(X, y)
model.score(X, y)
#Predict Output
predicted= model.predict(x_test)
R Code
library(rpart)
x <- cbind(x_train,y_train)
# grow tree
fit <- rpart(y_train ~ ., data = x,method="class")
summary(fit)
#Predict Output
predicted= predict(fit,x_test)
4.SVM(支持向量机)
这是一种分类方法。 在这个算法中,我们将每个数据项目绘制为n维空间中的一个点(其中n是拥有的特征数),每个特征的值是特定坐标的值。
例如,如果我们有一个人的“高度”和“头发长度”这两个特征,我们首先将这两个变量绘制在二维空间中,其中每个点都有两个坐标(这些坐标称为支持向量)
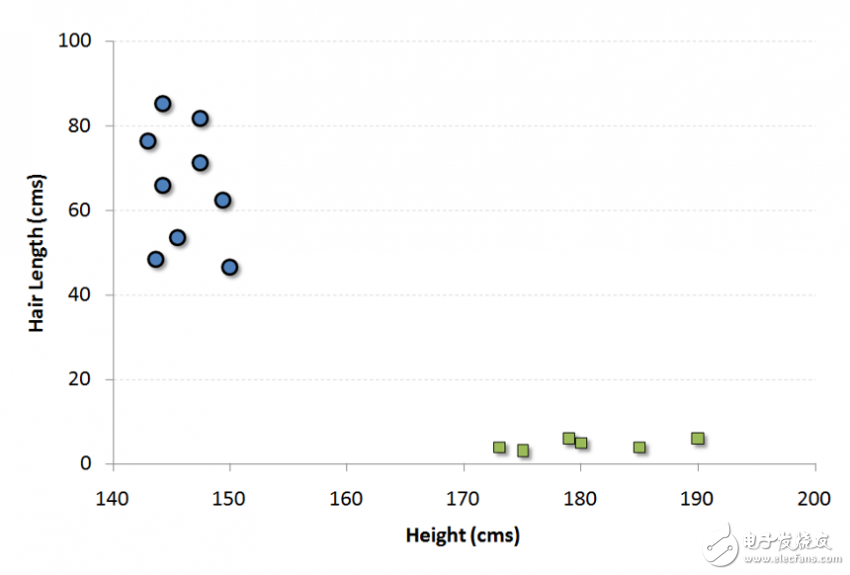
现在,我们将找到一些可以将数据分割成两类的线。 而我们想要的线,就是使得两组数据中最近点到分割线的距离最长的线。
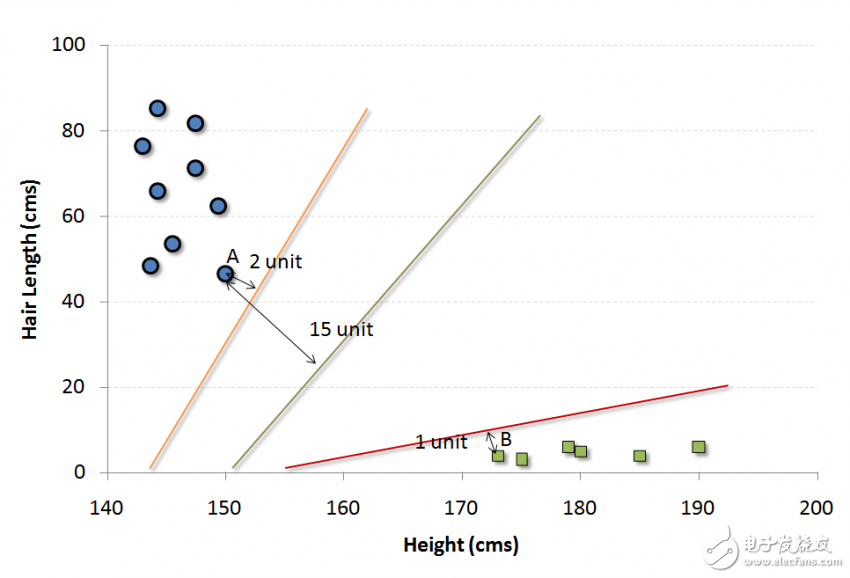
在上述示例中,将数据分成两个不同分类的组的线是黑线,因为两个最接近的点距离线最远(红线也可以,但不是一最远)。 这条线是我们的分类器, 然后根据测试数据位于线路两边的位置,我们可以将新数据分类为什么类别。
Python Code
#Import Library
from sklearn import svm
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create SVM classification object
model = svm.svc() # there is various option associated with it, this is simple for classification. You can refer link, for mo# re detail.
# Train the model using the training sets and check score
model.fit(X, y)
model.score(X, y)
#Predict Output
predicted= model.predict(x_test)
R Code
library(e1071)
x <- cbind(x_train,y_train)
# Fitting model
fit <-svm(y_train ~ ., data = x)
summary(fit)
#Predict Output
predicted= predict(fit,x_test)
5. 朴素贝叶斯
它是基于贝叶斯定理的分类技术,假设预测因子之间是独立的。 简单来说,朴素贝叶斯分类器假设类中特定特征的存在与任何其他特征的存在无关。 例如,如果果实是红色,圆形,直径约3英寸,则果实可能被认为是苹果。 即使这些特征依赖于彼此或其他特征的存在,一个朴素的贝叶斯分类器将考虑的是所有属性来单独地贡献这个果实是苹果的概率。
朴素贝叶斯模型易于构建,对于非常大的数据集尤其有用。 除了简单之外,朴素贝叶斯也被称为超高级分类方法。














 工商网监
工商网监
评论