 电子发烧友App
电子发烧友App


例子
从上图中,我们可以看到,A,B,C,D,E是五个在图中点。而灰色的点是我们的种子点,也就是我们用来找点群的点。有两个种子点,所以K=2。
然后,K-Means的算法如下:
随机在图中取K(这里K=2)个种子点。
然后对图中的所有点求到这K个种子点的距离,假如点Pi离种子点Si最近,那么Pi属于Si点群。(上图中,我们可以看到A,B属于上面的种子点,C,D,E属于下面中部的种子点)
接下来,我们要移动种子点到属于他的“点群”的中心。(见图上的第三步)
然后重复第2)和第3)步,直到,种子点没有移动(我们可以看到图中的第四步上面的种子点聚合了A,B,C,下面的种子点聚合了D,E)。
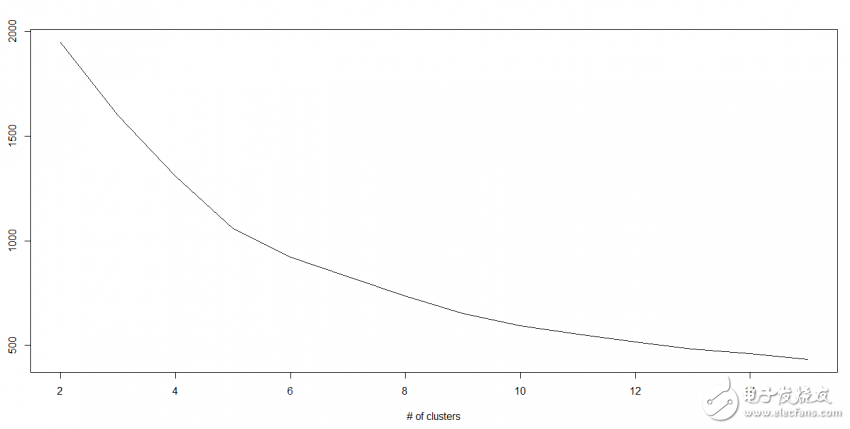
K值如何确定
在实际应用中,由于Kmean一般作为数据预处理,或者用于辅助分聚类贴标签。所以k一般不会设置很大。可以通过枚举,令k从2到一个固定值如10,在每个k值上重复运行数次kmeans(避免局部最优解),并计算当前k的平均轮廓系数,最后选取轮廓系数最大的值对应的k作为最终的集群数目。参考
我们知道随着群集数量的增加,该值不断减少,但是如果绘制结果,则可能会发现平方距离的总和急剧下降到k的某个值,然后再慢一些。 在这里,我们可以找到最佳聚类数。
Python Code
#Import Library
from sklearn.cluster import KMeans
#Assumed you have, X (attributes) for training data set and x_test(attributes) of test_dataset
# Create KNeighbors classifier object model
k_means = KMeans(n_clusters=3, random_state=0)
# Train the model using the training sets and check score
model.fit(X)
#Predict Output
predicted= model.predict(x_test)
R Code
library(cluster)
fit <- kmeans(X, 3) # 5 cluster solution
8. Random Forest(随机树林)
随机森林(Random Forest)是一个包含多个决策树的分类器, 其输出的类别由个别树输出类别的众数而定。(相当于许多不同领域的专家对数据进行分类判断,然后投票)
感觉原文没有将什么实质内容,给大家推进这一篇Random Forest入门
9. 降维算法
在过去的4-5年中,数据挖掘在每个可能的阶段都呈指数级增长。 公司/政府机构/研究机构不仅有新的来源,而且他们正在非常详细地挖掘数据。
例如:电子商务公司正在捕获更多关于客户的细节,例如人口统计,网络爬网历史,他们喜欢或不喜欢的内容,购买历史记录,反馈信息等等,给予他们个性化的关注,而不是离你最近的杂货店主。
作为数据科学家,我们提供的数据还包括许多功能,这对建立良好的稳健模型是非常有用的,但是有一个挑战。 你如何识别出1000或2000年高度重要的变量? 在这种情况下,维数降低算法可以帮助我们与决策树,随机森林,PCA,因子分析,基于相关矩阵,缺失值比等的其他算法一起使用。
要了解更多有关此算法的信息,您可以阅读 “Beginners Guide To Learn Dimension Reduction Techniques“.
Python Code
#Import Library
from sklearn import decomposition
#Assumed you have training and test data set as train and test
# Create PCA obeject pca= decomposition.PCA(n_components=k) #default value of k =min(n_sample, n_features)
# For Factor analysis
#fa= decomposition.FactorAnalysis()
# Reduced the dimension of training dataset using PCA
train_reduced = pca.fit_transform(train)
#Reduced the dimension of test dataset
test_reduced = pca.transform(test)
For more detail on this, please refer .
R Code
library(stats)
pca <- princomp(train, cor = TRUE)
train_reduced <- predict(pca,train)
test_reduced <- predict(pca,test)
10. Gradient Boosting & AdaBoost
当我们处理大量数据以预测高预测能力时,GBM&AdaBoost是更加强大的算法。 Boosting是一种综合学习算法,它结合了几个基本估计器的预测,以提高单个估计器的鲁棒性。 它将多个弱或平均预测值组合到一个强大的预测变量上。 这些提升算法在数据科学比赛中总是能够很好地运行,如Kaggle,AV Hackathon,CrowdAnalytix。
More: Know about Gradient and AdaBoost in detail
Python Code
#Import Library
from sklearn.ensemble import GradientBoostingClassifier
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create Gradient Boosting Classifier object
model= GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1, random_state=0)
# Train the model using the training sets and check score
model.fit(X, y)
#Predict Output
predicted= model.predict(x_test)
R Code
library(caret)
x <- cbind(x_train,y_train)
# Fitting model
fitControl <- trainControl( method = "repeatedcv", number = 4, repeats = 4)
fit <- train(y ~ ., data = x, method = "gbm", trControl = fitControl,verbose = FALSE)
predicted= predict(fit,x_test,type= "prob")[,2]














 工商网监
工商网监
评论