完善资料让更多小伙伴认识你,还能领取20积分哦,立即完善>
电子发烧友网技术文库为您提供最新技术文章,最实用的电子技术文章,是您了解电子技术动态的最佳平台。
机器学习是一种方法,利用算法来让机器可以自我学习和适应,而且不需要明确地编程。在许多应用中,需要机器使用历史数据训练模型,然后使用该模型来对新数据进行预测或分类...
在入门级使用的数据集很小,可以放入主内存中。只需几行代码即可应用此类操作。在此阶段数据包括Audio、Image、Time-series和Text等类型。...
人工智能是机器做出决策的能力,就像人类做决定一样。机器可以对反复出现的情况进行处理,并选择以不同的方式进行处理,即使从表面上看,每次的情况似乎都是相同的。...
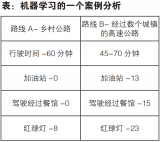
智能网络正日益成为5G 网络和服务的组成部分,其范围延伸至四个关键领域:首先是对智能网络概念的基础理解,其次是架构框架,然后是逐步实现人工智能网络的层次划分,最后是人工智能网络的案例研究。...
通用人工智能与机器人产业正处在快速发展、互相融合促进的战略机遇期,作为两大领域交叉的核心应用,具身智能有望在未来取得快速发展。具身智能将促使智能体具备自主规划、决策、行动、执行等能力,实现人工智能的能力进阶。...
深度学习和神经网络的区别在于隐藏层的深度。一般来说,神经网络的隐藏层要比实现深度学习的系统浅得多,而深度学习的在隐藏层可以有很多层。...

了如何基于相机投影模型生成BEV图像,并从中提取纹理,然后将纹理像素投影回原始点云,并使用损失优化方法。投影模型利用相机的姿态和内参矩阵,将地面坐标系的点投影到相机图像平面上。...

深度学习有提升战斗机、潜艇、无人机、卫星监视系统等复杂军事系统的自主性的潜力,但它也可能使这些系统变得更加复杂、更加难以解释。...

在Transformer中,注意力图的某些头部并不总是像Tacotron 2中那样是对角线的。因此,我们需要选择在哪些位置应用引导性注意力损失[24]。-使用Transformer进行解码的速度也比使用RNN慢(每帧6.5毫秒 vs 单线程CPU上每帧78.5毫秒)。...
随着人工智能模型创作虚假视频的逼真程度不断提高,深度伪造技术日益被视为“巨大的社会威胁”。例如,一个名为ModelScope的新型创意人工智能系统现在已经可以根据文本提示制作短视频。...
为什么AGI这样史诗级的革命,背后的核心推手竟然是OpenAI这样的创业公司?OpenAI到底做对了什么?...
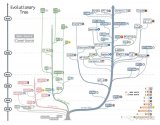
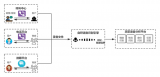
基于上述诸多优势,爱芯元智形成了拥有平台层、模型层、应用层三层架构的算力平台,平台层即软件+芯片的人工智能算力平台,模型层即Transformer大模型、应用层则包括智慧城市、智能驾驶、智能IOT三大应有赛道。...

58自研语音识别引擎,最初是基于Kaldi框架进行开发,在自研初期上线了架构1.0版本,后续以降低机器资源、提升资源利用率、优化性能为目标进行了升级重构,上线了架构2.0版本。...
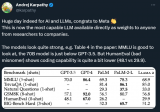
在几乎所有基准上,Llama 2 70B 的结果均与谷歌 PaLM (540B) 持平或表现更好,不过与 GPT-4 和 PaLM-2-L 的性能仍存在较大差距。...
为了打击深度伪造,该算法不需要对特定算法生成的深度伪造音频进行采样。那不勒斯大学的威尔多利瓦开发了另一类算法。在训练过程中,该算法学习寻找讲话者的生物识别标志。...

介绍GPT-4 详细参数及英特尔发布 Gaudi2 加速器相关内容,对大模型及 GPU 生态进行探讨和展望。英特尔发布高性价比Gaudi2加速卡GPT4详细参数分析。...

YOLO算法从总体上看,是单阶段端到端的基于anchor-free的检测算法。将图片输入网络进行特征提取与融合后,得到检测目标的预测框位置以及类概率。而YOLOv5相较前几代YOLO算法,模型更小、部署灵活且拥有更好的检测精度和速度,适合实时目标检测。...
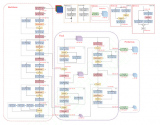
首先C-eval本身题目是公开的离线测试,答案是不可见在线提交的形式来评测,这样能一定程度上规避泄漏的问题。...

由于噪声和退化,并非所有正确匹配都能给出良好的姿态。之前的操作仅保证具有判别性高的描述子的特征点有更高的匹配分数,并且首先被识别以参与姿态估计,但忽略了鲁棒姿态估计所需的几何要求。...

关注我们的微信

下载发烧友APP

电子发烧友观察

版权所有 © 湖南华秋数字科技有限公司
长沙市望城经济技术开发区航空路6号手机智能终端产业园2号厂房3层(0731-88081133)
电子发烧友 (电路图) 湘公网安备43011202000918 工商网监
湘ICP备2023018690号-1
工商网监
湘ICP备2023018690号-1




