完善资料让更多小伙伴认识你,还能领取20积分哦,立即完善>
电子发烧友网技术文库为您提供最新技术文章,最实用的电子技术文章,是您了解电子技术动态的最佳平台。
数据集的任何变化都将提供一个不同的估计值,若使用统计方法过度匹配训练数据集时,这些估计值非常准确。一个一般规则是,当统计方法试图更紧密地匹配数据点,或者使用更灵活的方法时,偏差会减少,但方差会增加。...

最快的存储器类型是SRAM,但每个SRAM单元需要六个晶体管,因此SRAM在SoC内部很少使用,因为它会消耗大量的空间和功率。...

使用卷积神经网络(CNN)、支持向量机(SVM)、K近邻(KNN)和长短期记忆(LSTM)神经网络等四种不同的分类方法对三种步态模式进行自动分类。...

这些偏见特征可能导致模型在没有明确提及这些偏见的情况下,系统性地歪曲其推理过程,从而产生不忠实(unfaithful)的推理。...

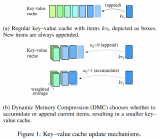
DMC通过一个决策变量(α)来有效地对输入序列进行分段,每个段落可以独立地决定是继续追加还是进行累积。这允许模型在不同段落之间动态调整内存使用。...
RZ/V2L还与RZ/G2L封装和引脚兼容。这使得RZ/G2L用户可轻松升级至RZ/V2L,以获得额外的人工智能功能,而无需修改系统配置,从而保持低迁移成本。...
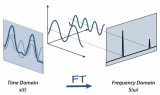
连续傅里叶变换(CFT)和离散傅里叶变换(DFT)是两个常见的变体。CFT用于连续信号,而DFT应用于离散信号,使其与数字数据和机器学习任务更加相关。...
训练经过约50次左右迭代,在训练集上已经能达到99%的正确率,在测试集上的正确率为90.03%,单纯的BP神经网络能够提升的空间不大了,但kaggle上已经有人有卷积神经网络在测试集达到了99.3%的准确率。...
通用大型语言模型(LLM)推理基准:研究者们介绍了多种基于文本的推理任务和基准,用于评估LLMs在不同领域(如常识、数学推理、常识推理、事实推理和编程)的性能。这些研究包括BIG-bench、HELM、SuperGLUE和LAMA等。...

基于神经网络技术,仅利用相对于传统态层析方法50%的测量基数目,即可实现平均保真度高达97.5%的开放光量子行走的完整混合量子态表征。...
GEAR框架通过结合三种互补的技术来解决这一挑战:首先对大多数相似幅度的条目应用超低精度量化;然后使用低秩矩阵来近似量化误差。...

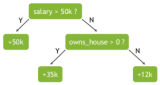
随机森林使用名为“bagging”的技术,通过数据集和特征的随机自助抽样样本并行构建完整的决策树。虽然决策树基于一组固定的特征,而且经常过拟合,但随机性对森林的成功至关重要。...
一对其余其实更加好理解,每次将一个类别作为正类,其余类别作为负类。此时共有(N个分类器)。在测试的时候若仅有一个分类器预测为正类,则对应的类别标记为最终的分类结果。...
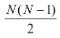
深度学习的效果在某种意义上是靠大量数据喂出来的,小目标检测的性能同样也可以通过增加训练集中小目标样本的种类和数量来提升。...

不同于上述工作从待干预模型自身抽取引导向量,我们意在从LLMs预训练过程的切片中构建引导向量来干预指令微调模型(SFT Model),试图提升指令微调模型的可信能力。...
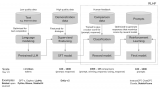
在大模型的发展史上,Scaling Law(规模律)发挥了核心作用,它是推动模型性能持续提升的主要动力。Scaling Law揭示了这样一个现象:较小的语言模型只能解决自然语言处理(NLP)中的部分问题,但随着模型规模扩大——参数数量增加至数十亿甚至数百亿,曾经在NLP领域中的棘手难题往往能得到有效...

首先看吞吐量,看起来没有什么违和的,在单卡能放下模型的情况下,确实是 H100 的吞吐量最高,达到 4090 的两倍。...
Nvidia是一个同时拥有 GPU、CPU和DPU的计算芯片和系统公司。Nvidia通过NVLink、NVSwitch和NVLink C2C技术将CPU、GPU进行灵活连接组合形成统一的硬件架构,并于CUDA一起形成完整的软硬件生态。...

人工智能在早期诞生了一个“不甚成功”的流派,叫做“人工神经网络”。这个技术的思路是,人脑的智慧无与伦比,要实现高级的人工智能,模仿人脑就是不二法门。...
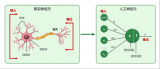
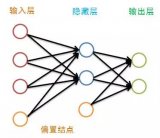
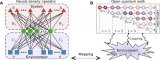
人工神经网络模型 AI芯片的核心原理基于人工神经网络,其中芯片内部的处理单元模拟了生物神经元的工作机制。每一个处理单元能够独立进行复杂的数学运算,例如权重乘以输入信号并累加,形成神经元的激活输出。...
关注我们的微信

下载发烧友APP

电子发烧友观察

版权所有 © 湖南华秋数字科技有限公司
长沙市望城经济技术开发区航空路6号手机智能终端产业园2号厂房3层(0731-88081133)
电子发烧友 (电路图) 湘公网安备43011202000918 工商网监
湘ICP备2023018690号-1
工商网监
湘ICP备2023018690号-1




