完善资料让更多小伙伴认识你,还能领取20积分哦,立即完善>
电子发烧友网技术文库为您提供最新技术文章,最实用的电子技术文章,是您了解电子技术动态的最佳平台。
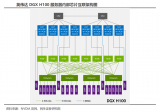
DXG 服务器配备 8 块 H100 GPU,6400亿个晶体管,在全新的 FP8 精度下 AI 性能比上一代高 6 倍,可提供 900GB/s 的带宽。...
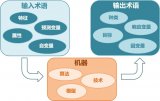
在监督式学习下,输入数据被称为“训练数据”,每组训练数据有一个明确的标识或结果,如对防垃圾邮件系统中“垃圾邮件”“非垃圾邮件”,对手写数字识别中的“1“,”2“,”3“,”4“等。...
从评测能力上来看,由于目前的评测数据集主要是利用人类试题及其标准答案进行评测,这种评价方式更偏向对推理能力的评估,存在评估结果和模型真实能力有⼀定偏差。...
作为通用序列模型的骨干,Mamba 在语言、音频和基因组学等多种模态中都达到了 SOTA 性能。在语言建模方面,无论是预训练还是下游评估,他们的 Mamba-3B 模型都优于同等规模的 Transformer 模型,并能与两倍于其规模的 Transformer 模型相媲美。...

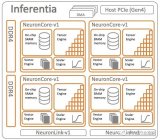
Trainium1 芯片于 2020 年 12 月发布,并以两个不同的实例(Trn1 和 Trn1n)发货。我们当时对 Trainium1 和2021 年 12 月的这些实例进行了尽可能多的分析,坦率地说,AWS 没有提供大量有关这些本土 AI 计算引擎的数据。...
作者对Transformer Block移除了各种参数,减少了15%参数量,提高了15%的训练速度,各个环节都有做充分的实验,但一些经验性得到的结论也并没有直接回答一些问题(如LN为什么影响收敛速度)。...
本文对比了多种基线方法,包括无监督域自适应的传统方法(如Pseudo-labeling和对抗训练)、基于检索的LM方法(如REALM和RAG)和情境学习方法(如In-context learning)。...

以太网是一种广泛使用的网络协议,但其传输速率和延迟无法满足大型模型训练的需求。相比之下,端到端IB(InfiniBand)网络是一种高性能计算网络,能够提供高达 400 Gbps 的传输速率和微秒级别的延迟,远高于以太网的性能。这使得IB网络成为大型模型训练的首选网络技术。...

在传统“小”模型方法中,需要对训练数据进行构建,例如训练一个分类模型,以便将用户的问题分类为不同的意图。同样,回答用户问题的方式也需要模型的处理,因为售后问题的多样性,有的需要直接回答,有的需要引导用户执行一系列步骤来解决。...

Copilot 最初是由 GitHub/Microsoft 和 OpenAI 合作推出的开发项目,致力于辅助软件开发人员编写代码,提供诸如将代码注释转换为可运行代码、自动完成代码块、代码重复部分以及整个方法和/或函数等功能。...

我们使用LLAMA2-7B作为实验的基础模型。我们主要评估将旧知识更新为新知识的能力,因此模型将首先在旧知识上进行为期3个时期的微调。表1中F-Learning中设置的超参数λ分别取值为0.3、0.7、0.1和1.5。...

PanopticNeRF-360是PanopticNeRF的扩展版本,借助3D粗标注快速生成大量的新视点全景分割和RGB图,并引入几何-语义联合优化来解决交叉区域的类别模糊问题,对于数据标注领域有一定价值。...

在研究人员选择的模型中,GPT-3 davinci(非指令微调)、GPT-3 textdavinci-001(指令微调)和GPT-3 textdavinci-003(InstructGPT)都是以前观察到过涌现能力的模型。这一选择主要是出于模型可用性的考虑。...
大模型当前以生成类应用为主,多模态是未来重点发展方向 企业用户是从应用视角出发,分成生成类应用、决策类应用和多模态应用。 受限于模型能力、应用效果等因素,当前阶段以生成类应用为主。...

未来全球服务器市场规模有望超万亿。长远来看,在国内外数据流量迅速增长以及公有云蓬勃发展的背景下,服务器作为云网体系中最重要的算力基础设施,未来存在巨大的成长空间,预计2027年市场规模将超万亿元(1891.4亿美元)。...

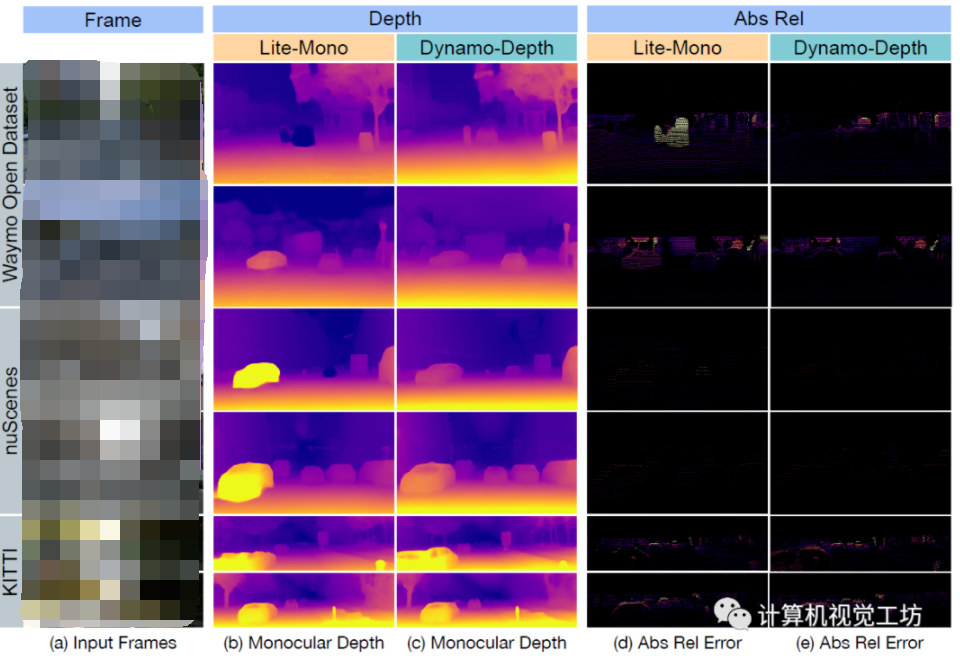
自监督单目深度估计的训练可以在大量无标签视频序列来进行,训练集获取很方便。但问题是,实际采集的视频序列往往会有很多动态物体,而自监督训练本身就是基于静态环境假设,动态环境下会失效。...
AI服务器按芯片类型可分为CPU+GPU、CPU+FPGA、CPU+ASIC等组合形式,CPU+GPU是目前国内的主要选择(占比91.9%);AI服务器的成本主要来自CPU、GPU等芯片,占比25%-70%不等,对于训练型服务器其80%以上的成本来源于CPU和GPU。...

关注我们的微信

下载发烧友APP

电子发烧友观察

版权所有 © 湖南华秋数字科技有限公司
长沙市望城经济技术开发区航空路6号手机智能终端产业园2号厂房3层(0731-88081133)
电子发烧友 (电路图) 湘公网安备43011202000918 工商网监
湘ICP备2023018690号-1
工商网监
湘ICP备2023018690号-1




