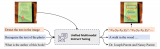
如上图所示,UniDoc基于预训练的视觉大模型及大语言模型,将文字的检测、识别、spotting(图....
![的头像]() CVer 发表于
CVer 发表于 08-31 15:29
•1172次阅读
为了解决这一问题,我们系统地分析了前景和背景在图像级跨域对齐中的重要性,并认识到在图像级跨域对齐中,....
![的头像]() CVer 发表于
CVer 发表于 08-30 15:30
•423次阅读

BEV自动驾驶感知好比一个从高处统观全局的“上帝视角”,将三维环境信息投影到二维平面,以俯视视角展示....
![的头像]() CVer 发表于
CVer 发表于 08-23 14:51
•833次阅读

根据这种方法,我们可以根据其他网络的权重来训练一个网络,这也许是一个用来做持续学习的好方法。同样有趣....
![的头像]() CVer 发表于
CVer 发表于 08-21 14:55
•366次阅读

随着基于激光雷达(LiDAR)的三维物体检测在机器人系统和自动驾驶汽车等各种应用中不断发展,解决在实....
![的头像]() CVer 发表于
CVer 发表于 08-18 15:19
•783次阅读

图像分解致力于通过完备的监督信号还原出包括噪声天气在内的所有图层,指向各图层的 multi-head....
![的头像]() CVer 发表于
CVer 发表于 08-15 15:16
•559次阅读

人体神经辐射场的目标是从 2D 人体图片中恢复高质量的 3D 数字人并加以驱动,从而避免耗费大量人力....
![的头像]() CVer 发表于
CVer 发表于 08-15 11:46
•652次阅读

想要注意的是,模型和数据集的详细信息并不是这里的主要关注点(它们只是为了尽可能简单,以便读者可以在自....
![的头像]() CVer 发表于
CVer 发表于 08-14 13:07
•609次阅读
SID[1] 首先提出一套完整的 benchmark 以及 dataset 进行RAW图像低光增强或....
![的头像]() CVer 发表于
CVer 发表于 08-11 15:47
•924次阅读

为实现模型性能和计算资源消耗、显存消耗、推理时延之间的平衡,Focus-DETR 利用精细设计的前景....
![的头像]() CVer 发表于
CVer 发表于 08-02 15:43
•356次阅读

即便如此,传统的 Transformer 依然存在局限。首要的一点,它们有着对于序列长度的二次时间复....
![的头像]() CVer 发表于
CVer 发表于 07-31 15:20
•862次阅读

然而,这一假设在机器人部署中通常是难以满足的,因为算法本身的延迟在机器人硬件上不可忽视,当算法完成当....
![的头像]() CVer 发表于
CVer 发表于 07-19 16:06
•584次阅读

构建这种表征的一个重要挑战是人体运动数据资源的异质性。运动捕捉(MoCap)系统提供了基于标记和传感....
![的头像]() CVer 发表于
CVer 发表于 07-19 14:23
•561次阅读

CLIP是一个通用的模型,考虑到下游数据分布的差异,对某个下游任务来说,CLIP提取的特征并不全是有....
![的头像]() CVer 发表于
CVer 发表于 07-19 14:19
•1283次阅读

如图1(a)所示,遥感图像中的物体检测器所使用的有限范围的背景往往会导致错误的分类。例如,在上层图像....
![的头像]() CVer 发表于
CVer 发表于 07-18 16:57
•951次阅读

人体动作预测是计算机视觉和图形学中的一个经典问题,旨在提升预测结果的多样性、准确性,并在自动驾驶、动....
![的头像]() CVer 发表于
CVer 发表于 07-17 16:56
•406次阅读

随着基于广泛数据训练的大模型兴起,上下文学习(In-Context Learning)已成为一种新的....
![的头像]() CVer 发表于
CVer 发表于 07-13 14:41
•549次阅读

这一惊人效果来自于发表在SIGGRAPH 2023会议上的 [Drag Your GAN] 论文(简....
![的头像]() CVer 发表于
CVer 发表于 07-13 14:36
•371次阅读
这个定律启发了基于运动的无监督分割。然而,Common Fate并不是物体性质的可靠指标:关节可动 ....
![的头像]() CVer 发表于
CVer 发表于 07-12 14:21
•591次阅读

文章称,他们从许多来源收集了大量有关 GPT-4 的信息,包括模型架构、训练基础设施、推理基础设施、....
![的头像]() CVer 发表于
CVer 发表于 07-12 14:16
•595次阅读

自 50 年前举办第一次会议以来, Technical Papers program 一直是 SIG....
![的头像]() CVer 发表于
CVer 发表于 07-11 14:34
•691次阅读

接着,LLM(大语言模型)根据这些内容编写代码,所生成代码与VLM(视觉语言模型)进行交互,指导系统....
![的头像]() CVer 发表于
CVer 发表于 07-11 14:31
•840次阅读

但是因为当时的技术所限,做出来的效果不好,于是他和OpenAI就改变了方向,开始做大语言模型了。最简....
![的头像]() CVer 发表于
CVer 发表于 07-11 11:17
•571次阅读
在半监督视频对象分割(VOS)和视频实例分割(VIS)方面,目前的主流方法处理未知数据时表现一般,是....
![的头像]() CVer 发表于
CVer 发表于 07-10 15:28
•483次阅读

VisProg目前支持20个模块,可实现图像理解、图像操作(包括生成)、知识检索和算术和逻辑操作等能....
![的头像]() CVer 发表于
CVer 发表于 07-10 15:26
•484次阅读

这篇论文揭示了 PaLM 或 GPT 在通过上下文学习解决视觉任务方面的能力,并提出了新方法 SPA....
![的头像]() CVer 发表于
CVer 发表于 07-09 15:35
•1030次阅读

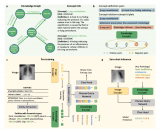
近年来,基于大数据预训练的多模态基础模型 (Foundation Model) 在自然语....
![的头像]() CVer 发表于
CVer 发表于 07-07 11:10
•576次阅读
过去业界也有推出一些数据集。他们主要有三个特点。第一个是数据规模小,第二个是都是基于GAN的,第三个....
![的头像]() CVer 发表于
CVer 发表于 07-04 15:53
•456次阅读

SIGGRAPH 博士论文奖设立于 2016 年,每年颁发给在计算机图形学和交互技术领域成功答辩并完....
![的头像]() CVer 发表于
CVer 发表于 07-04 10:55
•440次阅读

如今,计算机视觉社区已经广泛展开了对物体姿态的 6D 追踪和 3D 重建。本文中英伟达提出了同时对未....
![的头像]() CVer 发表于
CVer 发表于 07-03 11:24
•396次阅读






 工商网监
工商网监