







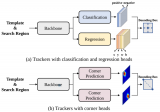



SAM-Adapter:首次让SAM在下游任务适应调优!
在这些基础模型中,Segment Anything Model(SAM)作为一个在大型视觉语料库上训....
从BLIP-2到SAM视觉语义金字塔+ChatGPT
怎么把图片表示成高质量文本一直是个热门的问题。传统的思路Show,and Tell 等 Image ....
马斯克离开OpenAI内幕:大权独揽想法被拒
OpenAI 于 2015 年成立,起初是一家非营利组织,得到了马斯克和里德・霍夫曼(Reid Ho....
港中大IDEA开源首个大规模全场景人体数据集Human-Art
然而,现有的计算机视觉任务、训练的数据集等大多只关注到了真实世界的照片,这导致相关模型在更丰富的场景....
StrucTexTv2:端到端文档图像理解预训练框架
视觉富文档理解技术例如文档分类、版式分析、表单理解、OCR以及信息提取,逐渐成为文档智能领域一个热门....
清华&美团提出稀疏Pairwise损失函数!ReID任务超已有损失函数!
ReID任务中的由于光照变化、视角改变和遮挡等原因会造成同一类中不同实例的视觉相似度很低(如图2所示....
这款编译器能让Python和C++一样快!
麻省理工学院计算机科学与人工智能实验室(CSAIL)的研究人员希望通过 Codon 来改变这一现状,....
大型语言模型综述全新出炉!从T5到GPT-4最全盘点
LLM 的涌现能力被正式定义为「在小型模型中不存在但在大型模型中出现的能力」,这是 LLM 与以前的....
DepGraph:任意架构的结构化剪枝,CNN、Transformer、GNN等都适用!
结构化剪枝是一种重要的模型压缩算法,它通过移除神经网络中冗余的结构来减少参数量,从而降低模型推理的时....
Meta提出Make-A-Video3D:一行文本,生成3D动态场景!
具体而言,该方法运用 4D 动态神经辐射场(NeRF),通过查询基于文本到视频(T2V)扩散的模型,....
LERF:当CLIP遇见NeRF!让自然语言与3D场景交互更直观
但自然语言不同,自然语言与 3D 场景交互非常直观。我们可以用图 1 中的厨房场景来解释,通过询问餐....
基于扩散模型的视频合成新模型,加特效杠杠的!
近日,曾参与创建 Stable Diffusion 的 Runway 公司推出了一个新的人工智能模型....
大脑视觉信号被Stable Diffusion复现成图像!
这项研究声称,只需用fMRI(功能磁共振成像技术,相比sMRI更关注功能性信息,如脑皮层激活情况等)....
ChatGPT正式上线对搜索引擎有什么影响
国内外两家搜索巨头急速冲刺,现在却还是投资了OpenAI的微软更快一步。倒也不奇怪,毕竟这种“搜索大....





 工商网监
工商网监