尽管Vision Transformer(ViTs)和自监督学习(SSL)越来越受欢迎,但在大多数任....
![的头像]() CVer 发表于
CVer 发表于 11-13 15:41
•465次阅读

深度学习的大模型时代已经来临,越来越多的大规模预训练模型在文本、视觉和多模态领域展示出杰出的生成和推....
![的头像]() CVer 发表于
CVer 发表于 11-08 16:20
•381次阅读

在top-1中,CODEFUSION的性能与自回归模型相媲美,甚至在某些情况下表现更出色,尤其是在P....
![的头像]() CVer 发表于
CVer 发表于 11-01 16:23
•554次阅读

相比于仅使用logits的蒸馏方法,同步使用模型中间层特征进行蒸馏的方法通常能取得更好的性能。然而在....
![的头像]() CVer 发表于
CVer 发表于 11-01 16:18
•649次阅读

在初始阶段我们尝试了多个GAN-based从mask生成image的模型 (e.g., OASIS[....
![的头像]() CVer 发表于
CVer 发表于 11-01 16:09
•562次阅读

现有方法往往是:用一个2D特征提取网络提取图像特征;用一个3D特征提取网络提取点云特征;然后根据pi....
![的头像]() CVer 发表于
CVer 发表于 10-29 17:14
•443次阅读

2023年10月18日(北京时间),PyTorch 基金会正式宣布华为作为Premier会员加入基金....
![的头像]() CVer 发表于
CVer 发表于 10-22 16:33
•896次阅读
效果怎么样呢?PaLI-3 在需要视觉定位文本理解和目标定位的任务上实现了新的 SOTA,包括 Re....
![的头像]() CVer 发表于
CVer 发表于 10-20 16:21
•1834次阅读

描述自动驾驶场景的条件是多维度的,包括:相机参数、物体框、路面地图以及对场景属性的语言描述(比如天气....
![的头像]() CVer 发表于
CVer 发表于 10-20 16:18
•248次阅读

用一句话来总结这个工作就是——我们提出了一种即插即用的loss S3IM(随机结构相似性),可以近乎....
![的头像]() CVer 发表于
CVer 发表于 10-13 15:59
•464次阅读

为了完成这两个任务,最为直觉,也是使用最多的方式就是:使用两个分支来完成这两件事,一个用来保留信息,....
![的头像]() CVer 发表于
CVer 发表于 10-10 17:18
•660次阅读

我们提出了一种全新的自监督代理任务 DropPos,首先在 ViT 前向过程中屏蔽掉大量的 posi....
![的头像]() CVer 发表于
CVer 发表于 10-10 17:10
•502次阅读

LanguageMPC首次将LLM应用于驾驶场景,并设计了将文字形式高层决策转化为可操作驾驶行为的方....
![的头像]() CVer 发表于
CVer 发表于 10-10 15:57
•507次阅读

最后,可能大家从上面一段论述中也已经能感觉出来了,许多大佬们正把embodied AI作为一个最终的....
![的头像]() CVer 发表于
CVer 发表于 10-08 16:16
•566次阅读

本文将空间条件中物体的形状、位置以及它们之间的关系等性质总结为视觉先验(Visual Prior),....
![的头像]() CVer 发表于
CVer 发表于 09-26 16:14
•451次阅读
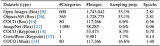
目前为止,OpenAI还没有对爆料中的传闻做出回应,但此前发布过多模态模型测试。CEO奥特曼在回应有....
![的头像]() CVer 发表于
CVer 发表于 09-20 17:34
•973次阅读

进一步使用大核卷积使得 FastViT 精度得到提升,而且不怎么影响延时。在移动设备和 ImageN....
![的头像]() CVer 发表于
CVer 发表于 09-20 17:12
•513次阅读

近来去噪扩散概率模型 Denoising diffusion probabilistic model....
![的头像]() CVer 发表于
CVer 发表于 09-19 16:02
•2491次阅读

基于MoCo[3]的框架,该文提出了用于文本识别的关系对比学习框架(RCLSTR)。如下图所示:1、....
![的头像]() CVer 发表于
CVer 发表于 09-14 17:21
•452次阅读

如下图,SCConv 由两个单元组成,即空间重构单元 (SRU) 和信道重构单元 (CRU) ,两个....
![的头像]() CVer 发表于
CVer 发表于 09-14 17:05
•1647次阅读
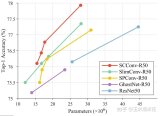
最近,马毅教授团队探索了基于Transformer架构的模型中涌现分割能力是否仅仅是复杂的自监督学习....
![的头像]() CVer 发表于
CVer 发表于 09-14 15:58
•361次阅读

一般性地,输入数据可以被表征为由序列维度(sequential)和通道维度(channel)组成的二....
![的头像]() CVer 发表于
CVer 发表于 09-12 16:40
•290次阅读
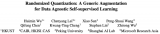
事实上,这并非唯一案例。自pubpeer不完全统计,4个月以来就有十几篇含有「Regenerate ....
![的头像]() CVer 发表于
CVer 发表于 09-12 16:22
•486次阅读
本文提出了新型的可控光照增强框架,主要采用了条件扩散模型来控制任意区域的任意亮度增强。通过亮度控制模....
![的头像]() CVer 发表于
CVer 发表于 09-11 17:20
•590次阅读

使用主动学习进行遥感目标检测旨在通过从大型未标记数据集中选择信息量丰富的样本来降低标注成本,从而训练....
![的头像]() CVer 发表于
CVer 发表于 09-10 10:02
•481次阅读

近期,火热的扩散模型也被广泛应用于多模态合成与编辑任务。例如效果惊人的DALLE-2和Imagen都....
![的头像]() CVer 发表于
CVer 发表于 09-05 16:06
•531次阅读

现有的视频目标分割(VOS)数据集主要关注于短时视频,平均时长在3-5秒左右,并且视频中的物体大部分....
![的头像]() CVer 发表于
CVer 发表于 09-04 16:33
•662次阅读

另外,采访中,Suleyman还爆出了很多自己在DeepMind和Inflection AI工作时的....
![的头像]() CVer 发表于
CVer 发表于 09-04 16:28
•546次阅读

在这些情况下, 传感器自带的噪声、无纹理的黑暗区域和反光等不利因素都违反了基于监督和自监督学习方法的....
![的头像]() CVer 发表于
CVer 发表于 09-04 16:14
•496次阅读

为了让大家更好的理解 Karpathy 的内容。我们先介绍一下「Speculative decodi....
![的头像]() CVer 发表于
CVer 发表于 09-04 15:43
•574次阅读



 工商网监
湘ICP备 2023018690 号
工商网监
湘ICP备 2023018690 号

