SIGGRAPH 博士论文奖设立于 2016 年,每年颁发给在计算机图形学和交互技术领域成功答辩并完....
![的头像]() CVer 发表于
CVer 发表于 07-04 10:55
•1024次阅读

如今,计算机视觉社区已经广泛展开了对物体姿态的 6D 追踪和 3D 重建。本文中英伟达提出了同时对未....
![的头像]() CVer 发表于
CVer 发表于 07-03 11:24
•673次阅读

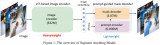
导读 本文提出一种"解耦蒸馏"方案对SAM的ViT-H解码器进行蒸馏,同时所得轻量级编码器可与SAM....
![的头像]() CVer 发表于
CVer 发表于 06-30 10:59
•1383次阅读
动动鼠标,让图片变「活」,成为你想要的模样。 在 AIGC 的神奇世界里,我们可以在图像上通过「拖曳....
![的头像]() CVer 发表于
CVer 发表于 06-30 10:57
•544次阅读
对于训练好的图像分类器,能让其可靠地在开放世界中工作的一个关键能力便是检测未知的、分布外的(out-....
![的头像]() CVer 发表于
CVer 发表于 06-28 15:57
•915次阅读

通过将分割⼀切任务重新划分为全实例分割和提⽰指导选择两个⼦任务,⽤带实例分割分⽀的常规 CNN 检测....
![的头像]() CVer 发表于
CVer 发表于 06-28 14:33
•1837次阅读
之前的模型大多利用手工制作的视觉线索特征,如颜色/亮度对比度、边缘和形状等,最近也有一些方法转向基于....
![的头像]() CVer 发表于
CVer 发表于 06-27 14:37
•477次阅读

然而生成图表也面临一些挑战,它需要表示框、箭头、文本等离散组件之间的复杂关系。与生成自然图像不同,论....
![的头像]() CVer 发表于
CVer 发表于 06-27 14:32
•631次阅读

1. 研究动机 图像分割旨在将具有不同语义的像素进行分类进而分组,例如类别或实例,近年来取得飞速的发....
![的头像]() CVer 发表于
CVer 发表于 06-26 10:39
•603次阅读

本文旨在更好地理解基于 Transformer 的大型语言模型(LLM)的内部机制,以提高它们的可靠....
![的头像]() CVer 发表于
CVer 发表于 06-25 15:08
•1600次阅读

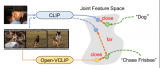
本文提出了一种新的CLIP向视频领域的迁移方法,找到模型泛化和专用化之间的平衡,让模型既能识别微调时....
![的头像]() CVer 发表于
CVer 发表于 06-25 15:04
•1207次阅读
在传统的三维物体检测任务中,前景物体通常由三维边界框表示。然而,这种方法存在一些弊端,一方面,现实世....
![的头像]() CVer 发表于
CVer 发表于 06-21 14:04
•1025次阅读

在上周复旦大学邱锡鹏团队提交的论文《Full Parameter Fine-tuning for L....
![的头像]() CVer 发表于
CVer 发表于 06-21 14:00
•936次阅读

尽管AI发展迅猛,但目前CV领域的许多任务仍然缺乏高质量的数据,3D尤甚。一个解决办法是用合成数据。....
![的头像]() CVer 发表于
CVer 发表于 06-20 14:47
•446次阅读

这篇论文的通讯作者是结构生物学家颜宁,主要从事与疾病相关的重要膜转运蛋白、电压门控离子通道的结构与工....
![的头像]() CVer 发表于
CVer 发表于 06-19 16:08
•634次阅读

面向真实 3D 物体的感知、理解、重建与生成是计算机视觉领域一直倍受关注的问题,也在近年来取得了飞速....
![的头像]() CVer 发表于
CVer 发表于 06-19 15:30
•1613次阅读

引言 距离上次的长篇大论,已经过去了半年有余。这段时间,对于AI业界甚至整个世界,都是惊心动魄的。在....
![的头像]() CVer 发表于
CVer 发表于 06-19 11:44
•736次阅读

我可以将最近的一篇数学预印本的前几页PDF输入GPT-4,让它生成半打有关该预印本的专家可能会提出的....
![的头像]() CVer 发表于
CVer 发表于 06-19 10:52
•545次阅读

本文介绍CVPR2023的中稿论文:Temporal Attention Unit: Towards....
![的头像]() CVer 发表于
CVer 发表于 06-19 10:27
•1594次阅读

在一些非自然图像中要比传统模型表现更好 CoOp 增加一些 prompt 会让模型能力进一步提升 怎....
![的头像]() CVer 发表于
CVer 发表于 06-15 16:36
•630次阅读

今日,Meta 推出了首个基于 LeCun 世界模型概念的 AI 模型。该模型名为图像联合嵌入预测架....
![的头像]() CVer 发表于
CVer 发表于 06-15 15:47
•414次阅读
图2是模型的整体结构图,它包含颜色感知背景提取网络(Color-aware Background E....
![的头像]() CVer 发表于
CVer 发表于 06-12 14:20
•1132次阅读

先随机采样两个视频帧,并进行非对称掩码操作;然后SiamMAE编码器网络对两个帧进行独立处理,最后使....
![的头像]() CVer 发表于
CVer 发表于 06-12 14:18
•669次阅读

Stable Diffusion (SD)是当前最热门的文本到图像(text to image)....
![的头像]() CVer 发表于
CVer 发表于 06-12 10:14
•878次阅读

【导读】 AI理论再进一步,破解ChatGPT指日可待? Transformer架构已经横扫了包....
![的头像]() CVer 发表于
CVer 发表于 06-12 10:11
•966次阅读

本文将空间条件中物体的形状、位置以及它们之间的关系等性质总结为视觉先验(Visual Prior),....
![的头像]() CVer 发表于
CVer 发表于 06-11 10:34
•407次阅读

RES在图形编辑、视频制作、人机交互和机器人等众多应用领域具有巨大潜力。目前,大多数现有方法都遵循在....
![的头像]() CVer 发表于
CVer 发表于 06-08 15:06
•527次阅读

现有的可控图片生成模型都是针对单一的模态进行设计,然而 Taskonomy [3] 等工作证明不同的....
![的头像]() CVer 发表于
CVer 发表于 06-08 15:01
•744次阅读

该研究提出了一个简单而有效的框架 Control-GPT,它利用 LLM 的强大功能根据文本 pro....
![的头像]() CVer 发表于
CVer 发表于 06-05 15:31
•932次阅读

ImageBind算是跨出了重要的一步,但我之前文章提了我的个人观点,就是采用小规模其他模态和图像的....
![的头像]() CVer 发表于
CVer 发表于 06-02 17:26
•1019次阅读




 工商网监
湘ICP备2023018690号-1
工商网监
湘ICP备2023018690号-1

