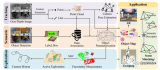
LOG-LIO的流程接收来自3D激光雷达和惯性测量单元(IMU)的输入,如图2所示。对于新的输入扫描....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 08-18 15:45
•723次阅读
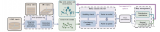
PnP是指根据2D-3D对应关系集合估计相机绝对位姿,集合最小的情况是P3P问题。P3P是将2D-3....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 08-18 15:40
•729次阅读
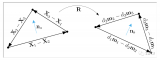
但是最近有一个团队就推出了这样的工作,也就是CMU、IIIT Hyderabad、MIT、AIML联....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 08-14 11:58
•584次阅读
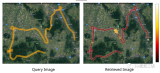
语义占用网格感知对于自动驾驶至关重要,因为自动驾驶车辆需要对3D城市场景进行细粒度感知。
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 08-14 09:37
•865次阅读

卡尔曼滤波(Kalman Filter),以下简称KF,是由Swerling(1958)和Kalma....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 08-10 09:58
•7835次阅读

说到纯视觉的自动驾驶方案,大家第一个想到的就是Tesla吧。的确,早在2021年,Tesla就已经实....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 08-07 16:34
•794次阅读

当车辆位于十字路口时,自车的路径实际上应该是根据信号灯来决定的。但是在图像上信号灯很小,周围车辆很大....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 08-07 15:07
•577次阅读
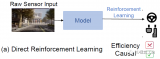
dToF(直接飞行时间)雷达的发展前景非常广阔。随着技术的不断进步和应用场景的增多,dToF雷达在许....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 08-07 10:31
•414次阅读
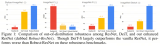
作者对多个 DETR 类检测器的 GFLOPs 和时延进行了对比分析,如图 1 所示。从图中发现,在....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 08-02 15:34
•518次阅读

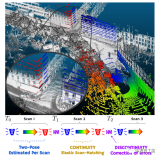
通过在每一帧扫描的开始和结束时刻联合优化两个姿势,并根据时间戳进行插值,使扫描进行弹性变形以与地图(....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 08-02 15:29
•890次阅读
dToF(直接飞行时间)雷达的发展前景非常广阔。
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 07-31 09:22
•2177次阅读

WormGPT 基于 2021 年开源的 LLM GPT-J 模型开发,也是对话聊天机器人,可以处理....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 07-29 16:35
•1468次阅读
目标检测的结果可以和场景流估计结合,可以通过多任务框架将两个任务统一到一个网络框架中。例如,一种方法....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 07-29 16:27
•503次阅读
现有的文本到三维模型的生成方法通常使用NeRF等隐式表达,通过体积渲染将几何和外观耦合在一起,但在恢....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 07-29 16:25
•416次阅读

介绍 一般意义上,相机姿态估计通常依赖于如手工的特征检测匹配、RANSAC和束调整(BA)。在本文中....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 07-23 15:22
•1111次阅读

近日,梅卡曼德对AI视觉软件Mech-DLK进行了重磅升级。全新升级的Mech-DLK内置快速定位、....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 07-23 15:19
•893次阅读
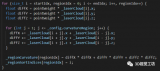
论文在III-B部分描述了论文方法背后的SLAM管道。论文的2D潜在先验网络(LPN)在III-C中....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 07-19 15:55
•443次阅读

导读 继卷积神经网络之后,Transformer又推进了图像识别的发展,成为视觉领域的又一主导。最近....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 07-17 14:35
•381次阅读
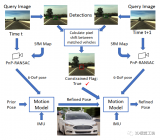
6自由度视觉定位是在给定先验三维地图和查询图像的情况下估计相机绝对姿态的任务。这是一个具有挑战性的研....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 07-17 14:30
•388次阅读
C++一直都被称作是最难学的计算机语言,笔者从业多年,也认为确实如此。相比于其他几种语言,单纯从语法....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 07-17 14:27
•377次阅读
深度学习在计算机视觉中的成功很大程度上是由卷积神经网络(CNNs)推动的。从AlexNet这一里程碑....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 07-17 14:25
•1043次阅读

本文建立了一个用于无人机距离估计的UAVDE数据集,通过UWB传感器获取两个无人机之间的距离。实验发....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 07-17 11:27
•1078次阅读
总的来说,框架实现稳健的数据关联、精确的物体参数化以及基于语义对象地图的高层应用,解决了对象SLAM....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 07-14 16:49
•586次阅读
VEnus算法对于反光柱导航的基本思路,其主要分为了高反点提取、高反点聚类查找中心、高反点与已知反光....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 07-14 15:37
•475次阅读

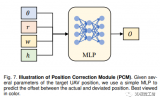
作者使用一个多头神经网络来参数化预测的占位概率和流向量。该网络以体素化的LiDAR数据、光栅地图和一....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 07-12 10:35
•374次阅读
主要利用点云数据的主轴方向进行配准。首先计算两组点云的协方差矩阵,根据协方差矩阵计算主要的特征分量,....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 07-10 15:16
•3622次阅读

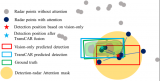
雷达以用于高级驾驶辅助系统(ADAS)多年。然而,尽管雷达在汽车行业中很流行,考虑到3D目标检测时,....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 07-10 14:55
•1902次阅读
文章采用了统一的B样条(Uniform B-Splines)来建模地面表面,这种方法对于不同的测量密....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 07-09 15:52
•499次阅读

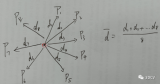
根据点云数据的某些属性或特征进行筛选,可以一次删除满足对输入的点云设定的一个或多个条件指标的所有的数....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 07-09 15:18
•3331次阅读
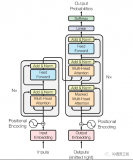
理解Transformer背后的理论基础,比如自注意力机制(self-attention), 位置编....
![的头像]() 3D视觉工坊 发表于
3D视觉工坊 发表于 07-09 14:35
•484次阅读





 工商网监
工商网监