这个方法之所以有效,是因为均匀分布帮助我们将Mq(x)提供的“封包”缩放到p(x)的概率密度函数。另....

考虑到强化学习[10]训练大语言模型的困难性,我们从语言建模的角度对大语言模型进行解毒。已有工作将解....

本篇内容是对于ACL‘23会议上陈丹琦团队带来的Tutorial所进行的学习记录,以此从问题设置....
多模态(Multimodality)是指在信息处理、传递和表达中涉及多种不同的感知模态或信息来源。这....

大型语言模型的出现极大地推动了自然语言处理领域的进步,但同时也存在一些局限性,比如模型可能会产生看似....
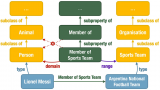
该研究同时提出了一个全新任务,图像对比 VQA (difference VQA):给定两张图片,回答....

现有大模型在预训练过程中都会加入书籍、论文等数据,那么在领域预训练时这两种数据其实也是必不可少的,主....
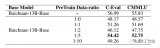
尽管开源大语言模型 (LLM) 及其变体(例如 LLaMA 和 Vicuna)取得了进步,但它们在执....

随着 Llama 2 的逐渐走红,大家对它的二次开发开始流行起来。前几天,OpenAI 科学家 Ka....

目前 DETR 类模型已经成为了目标检测的一个主流范式。但 DETR 算法模型复杂度高,推理速度低,....

苏神最早提出的扩展LLM的context方法,基于bayes启发得到的公式

如果你动手跑几次ppo的过程就发现了,大模型的强化学习非常难以训练,难以训练不仅仅指的是费卡,还是指....
最近,大语言模型(Large Language Models, LLMs)的快速发展带来了自然语言处....
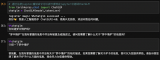
ChatGLM2-6b是清华开源的小尺寸LLM,只需要一块普通的显卡(32G较稳妥)即可推理和微调,....

在大模型出来之前,人和数据怎么发生关系?人不能直接与数据发生关系,需要通过一个中介,这个中介就是应用....
LoRA微调是一种高效的融入学习算法。类似人类把新知识融入现有知识体系的学习过程。学习时无需新知识特....
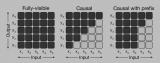
通过线性插值RoPE扩张LLAMA context长度最早其实是在llamacpp项目中被人发现,有....
LLM 是黑箱模型,缺乏可解释性,因此备受批评。LLM 通过参数隐含地表示知识。因此,我们难以解释和....

现在chatglm2的代码针对这两个问题已经进行了改善,可以认为他就是典型的decoder-only....
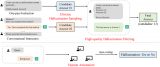
对齐:我们提出了一种混合对齐策略,以确保实体在话语和信念状态中都能被替换为所需的翻译。具体而言,我们....
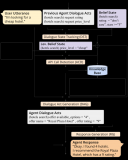
此外,BATGPT还采用了强化学习方法,从AI和人类反馈中学习,以进一步提高模型的对齐性能。这些方法....

大语言模型目前已经成为学界研究的热点。我们统计了arXiv论文库中自2018年6月以来包含关键词"语....

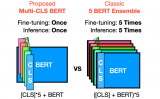
在 GLUE 和 SuperGLUE 数据集上进行了实验,证明了 Multi-CLS BERT 在提....
在大家不断升级迭代自家大模型的时候,LLM(大语言模型)对上下文窗口的处理能力,也成为一个重....

把大模型的训练门槛打下来!我们在单张消费级显卡上实现了多模态大模型(LaVIN-7B, LaVIN-....
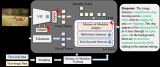
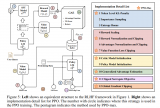
在这篇文章中,我们将尽可能详细地梳理一个完整的 LLM 训练流程。包括模型预训练(Pretr....

今天分享一篇普林斯顿大学的一篇文章,Tree of Thoughts: Deliberate Pro....

为了解决这一问题,本文提出了三个LLM模型——理解、经验和事实,将它们合成为一个组合模型。还引入了多....
一、概述 1 Motivation 构造instruction data非常耗时耗力,常受限于质量,....

近年来,大规模深度神经网络的显著成就彻底改变了人工智能领域,在各种任务和领域展示了前所未有的性能。这....
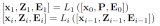



 工商网监
湘ICP备2023018690号-1
工商网监
湘ICP备2023018690号-1

