大模型由于其在各种任务中的出色表现而引起了广泛的关注。然而,大模型推理的大量计算和内存需求对其在资源....

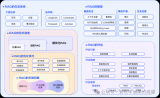
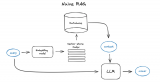
高级的RAG能很大程度优化原始RAG的问题,在索引、检索和生成上都有更多精细的优化,主要的优化点会集....
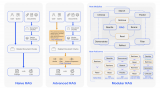
MoE 与 MoT:在专家混合中(左),每个令牌都被路由到不同的专家前馈层。在令牌混合(右)中,每组....
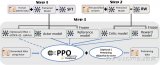
这篇论文试图解决的问题是大型预训练模型在下游任务中进行微调时出现的过拟合问题。尽管低秩适应(LoRA....

在选择k值时,较大的值会使生成的内容更具多样性,但可能会生成不合理的内容;较小的值则使生成的内容多样....

斯坦福大学此前提出的FlashAttention算法,能够在BERT-large训练中节省15%,将....
对于所有“基座”(Base)模型,–template 参数可以是 default, alpaca, ....
NLP上估计会帮助reduce overfitting, improve generalizatio....
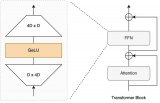
篇论文主要研究了大型语言模型(LLMs)中的一个现象,即在模型的隐藏状态中存在极少数激活值(acti....

对于语言模型(LLM)幻觉,知识图谱被证明优于向量数据库。知识图谱提供更准确、多样化、有趣、逻辑和一....

向量数据库是一组高维向量的集合,用于表示实体或概念,例如单词、短语或文档。向量数据库可以根据实体或概....
Meta 发布的 LLaMA 2,是新的 sota 开源大型语言模型 (LLM)。LLaMA 2 代....
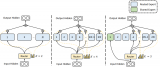
基于1.1中的思想,我们在V2中将原本的内外循环置换了位置(示意图就不画了,基本可以对比V1示意图想....

准确解释用户查询以检索相关的结构化数据是困难的,特别是在面对复杂或模糊的查询、不灵活的文本到SQL转....
通过SFT、DPO、RLHF等技术训练了领域写作模型。实测下来,在该领域写作上,强于国内大多数的闭源....
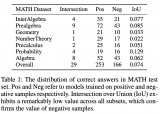
在思维链(CoT)提示的帮助下,大语言模型(LLMs)展现出强大的推理能力。然而,思维链已被证明是千....
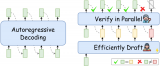
这个问题随着LLM规模的增大愈发严重。并且,如下左图所示,目前LLM常用的自回归解码(autoreg....
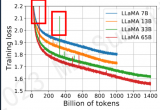
.通常CPT开始的阶段会出现一段时间的loss上升,随后慢慢收敛,所以学习率是一个很重要的参数,这很....
尽管大语言模型能力不断提升,但一个持续存在的挑战是它们具有产生幻象的倾向。本文构建了幻象评测基准Ha....
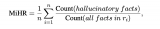
这是任何RAG流程的最后一步——基于我们仔细检索的所有上下文和初始用户查询生成答案。最简单的方法可能....
单模态大模型,通常大于100M~1B参数。具有较强的通用性,比如对图片中任意物体进行分割,或者生成任....

这个“gradient”怎么得到的了呢,这是个啥玩意,怎么还有梯度?注意,注意。人家是带引号的!比喻....
PaLM和GLM130b之前的解决办法是找到loss spike之前最近的checkpoint,更换....
Reward Model的初始化:6B的GPT-3模型在多个公开数据((ARC, BoolQ, Co....
vLLM 中,LLM 推理的 prefill 阶段 attention 计算使用第三方库 xform....

几天前,OpenAI「超级对齐」(Superalignment)团队发布了成立以来的首篇论文,声称开....
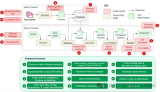
今天对百川的RAG方法进行解读,百川智能具有深厚的搜索背景,来看看他们是怎么爬RAG的坑的吧~
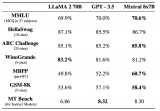
我们都知道,OpenAI 团队一直对 GPT-4 的参数量和训练细节守口如瓶。Mistral 8x7....
近期的大语言模型(LLM)在自然语言理解和生成上展现出了接近人类的强大能力,远远优于先前的BERT等....

随着开源预训练大型语言模型(Large Language Model, LLM )变得更加强大和开放....






 工商网监
工商网监