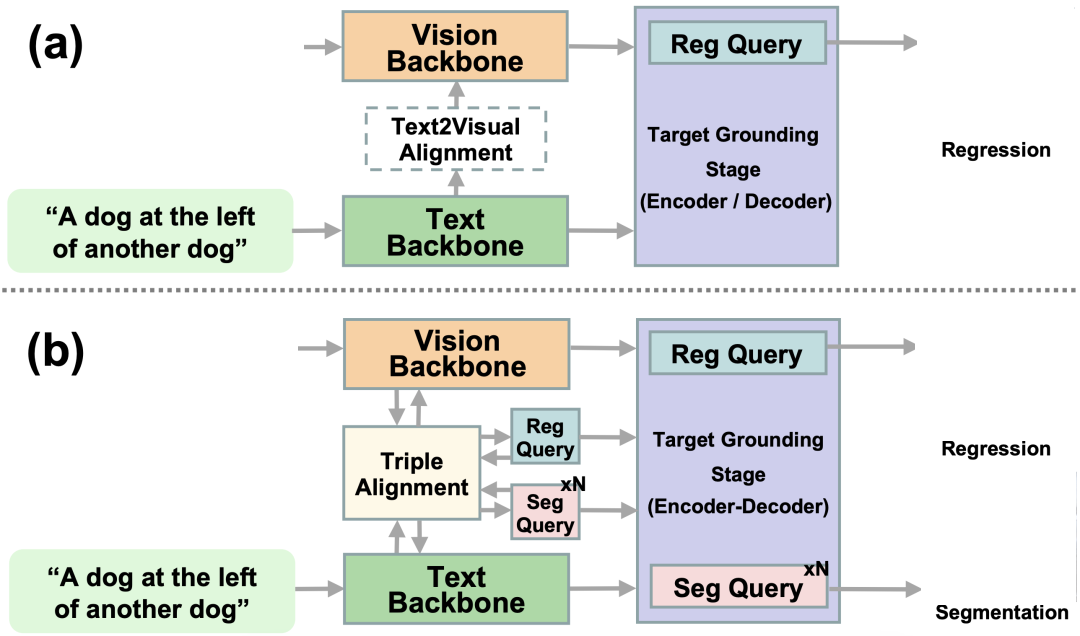
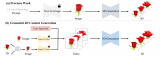
视觉定位(Visual Grounding)旨在基于自由形式的自然语言文本表达定位图像中的目标物体。....
![的头像]() CVer 发表于
CVer 发表于 10-28 13:59
•626次阅读
恶劣天气下,自动驾驶汽车也能准确识别周围物体了?!
![的头像]() CVer 发表于
CVer 发表于 10-28 13:52
•733次阅读
为了进一步评估研究方法在下游任务上(即分割、检测和实例分割)的效率,本文将骨干网与常用的特征金字塔网....
![的头像]() CVer 发表于
CVer 发表于 01-31 14:14
•2423次阅读
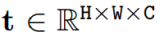
因此,本文研究者的目标是实现快速、逼真和通用的 3D 生成。为此,他们提出了 DMV3D。DMV3D....
![的头像]() CVer 发表于
CVer 发表于 01-30 16:20
•1030次阅读

我们主要探索了3D视觉中scale up模型参数量和统一模型架构的可能性。在NLP / 2D vis....
![的头像]() CVer 发表于
CVer 发表于 01-30 15:56
•1061次阅读

如上图所示,不再采用严格的一对一匹配,而是促使模型专注于一对多匹配,即从细粒度过渡到粗粒度。因此,首....
![的头像]() CVer 发表于
CVer 发表于 01-25 16:53
•801次阅读

为了解决这些挑战,我们提出了第一个大规模医学分割领域的公平性数据集, Harvard-FairSeg....
![的头像]() CVer 发表于
CVer 发表于 01-25 16:52
•648次阅读

另一个极端是,监督学习方法(即SupCE)会将所有这些图像视为单一类(如「金毛猎犬」)。这就忽略了这....
![的头像]() CVer 发表于
CVer 发表于 01-15 15:40
•628次阅读

Density-based方法:基于密度的方法通常采用预训练的模型来提取输入图像的有意义嵌入向量,测....
![的头像]() CVer 发表于
CVer 发表于 01-11 16:02
•1705次阅读

之前,将图像转换为3D的方法通常采用Score Distillation Sampling (SDS....
![的头像]() CVer 发表于
CVer 发表于 01-08 16:13
•641次阅读
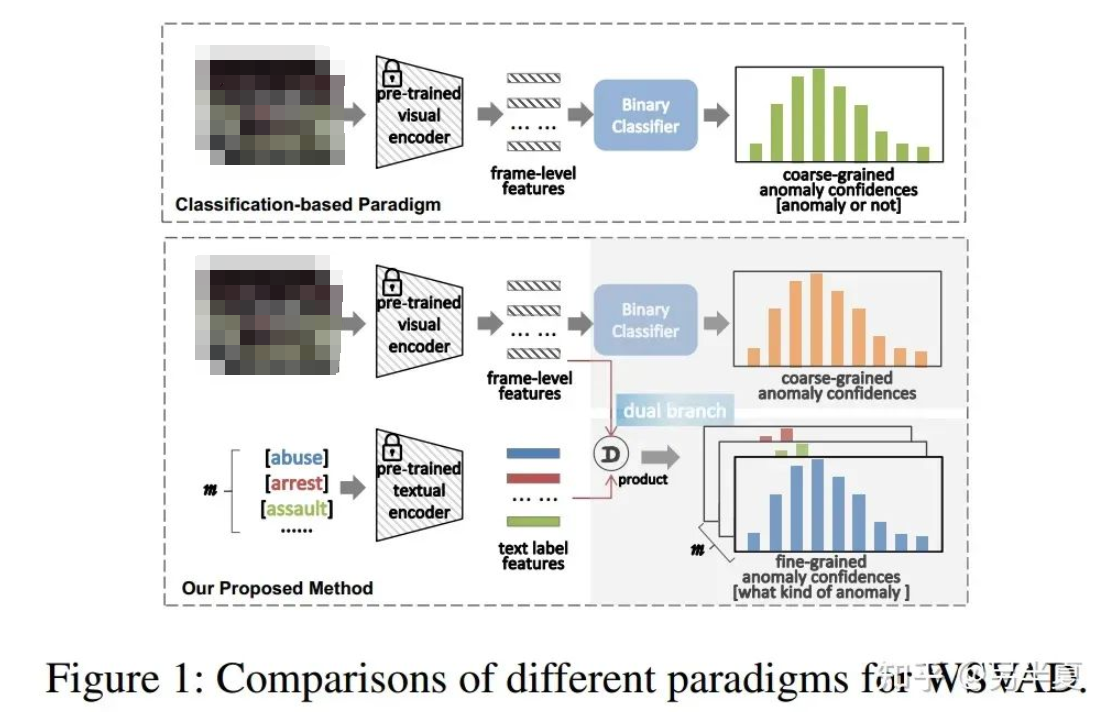
现有的基于计算机视觉的工业异常检测技术包括基于特征的、基于重构的和基于合成的技术。最近,扩散模型因其....
![的头像]() CVer 发表于
CVer 发表于 01-08 14:55
•1708次阅读

尽管3D和视频生成取得了飞速的发展,由于缺少高质量的4D数据集,4D生成始终面临着巨大的挑战。
![的头像]() CVer 发表于
CVer 发表于 01-04 15:57
•1101次阅读
LGT Adapter由局部关系Transformer和全局关系图卷积串联组成。考虑到常规的Tran....
![的头像]() CVer 发表于
CVer 发表于 01-02 15:20
•1012次阅读
一类常见的 Refinement 方法是 Model-Specific 的,其通过在已有分割模型中引....
![的头像]() CVer 发表于
CVer 发表于 12-28 11:24
•1827次阅读

最经典的原始NeRF为例,局部隐蔽场通过NeRF的MLP网络产生,与原始NeRF的两个输出color....
![的头像]() CVer 发表于
CVer 发表于 12-21 16:43
•1410次阅读
委员会说:「一些样品在 100 摄氏度时的电阻率发生了急剧变化,然而,我们认为相变是由(样品中的)杂....
![的头像]() CVer 发表于
CVer 发表于 12-19 11:38
•965次阅读

然而CLIP必须以整张图片作为输入并进行特征提取,无法关注到指定的任意区域。然而,自然的2D图片中往....
![的头像]() CVer 发表于
CVer 发表于 12-10 10:28
•1208次阅读

它有望超越条件图像生成,并推动诸如分子设计或药物发现这种不需要人类给注释的应用往前发展(这也是为什么....
![的头像]() CVer 发表于
CVer 发表于 12-10 10:24
•1089次阅读
在损失函数上,研究者从自然语言社区汲取灵感,即掩码 token 建模已经「让位给了」序列自回归预测方....
![的头像]() CVer 发表于
CVer 发表于 12-05 15:34
•812次阅读

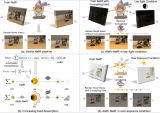
一是缺乏泛化能力。为了实现更好的超分效果,通常需要针对特定场景使用特定传感器采集到的数据来进行模型训....
![的头像]() CVer 发表于
CVer 发表于 12-04 16:22
•834次阅读

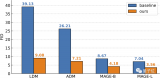
下图展示了Monkey的卓越性能,在 18 个不同的数据集上进行测试的结果表明,Monkey能够很好....
![的头像]() CVer 发表于
CVer 发表于 12-04 15:33
•1457次阅读

在时空超分中,除了 I0.5{HR}, 我们还要得到 I0{HR}, I1{HR},如果把它们看成三....
![的头像]() CVer 发表于
CVer 发表于 11-29 16:31
•931次阅读

相比于常规的三通道 RGB 图像,高光谱图像包含几十上百个波段,从而捕获了关于成像场景更丰富的信息。....
![的头像]() CVer 发表于
CVer 发表于 11-29 15:43
•594次阅读

场景文本识别(Scene Text Recognition)的目标是将图像中的文本内容提取出来。实际....
![的头像]() CVer 发表于
CVer 发表于 11-27 16:28
•1035次阅读

一个直接的解决方案是设计一个特定的训练方案,可以在不可利用的数据上进行训练。这是不太理想的,因为它只....
![的头像]() CVer 发表于
CVer 发表于 11-25 14:46
•740次阅读
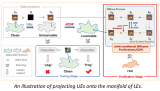
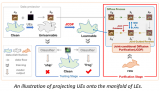
在深度学习领域,网络上充斥着大量可自由访问的数据,其中包括像ImageNet和MS-Celeb-1M....
![的头像]() CVer 发表于
CVer 发表于 11-25 14:45
•637次阅读
最近,大型多模态(即视觉和语言)模型(LMM)在图像描述、视觉理解、视觉推理等多种视觉任务上表现出了....
![的头像]() CVer 发表于
CVer 发表于 11-21 16:08
•2365次阅读

扩散模型和 GAN 的混合模型最早是英伟达的研究团队在 ICLR 2022 上提出的 DDGAN(《....
![的头像]() CVer 发表于
CVer 发表于 11-21 16:02
•750次阅读

神经辐射场作为近期一个广受关注的隐式表征方法,能合成照片级真实的多视角图像。但因为其隐式建模的性质,....
![的头像]() CVer 发表于
CVer 发表于 11-20 16:56
•688次阅读

在机器视觉和机器人领域的许多前沿应用中,学习准确且高效的三维形状表达是十分重要的。然而,现有的基于三....
![的头像]() CVer 发表于
CVer 发表于 11-17 16:23
•835次阅读




 工商网监
湘ICP备2023018690号-1
工商网监
湘ICP备2023018690号-1

